
We began using Apache Spark in 2015 as an integral component of our underlying data processing infrastructure. We chose to use it for the following reasons:
- It’s a single platform that allows us to implement both real-time streaming as well as offline batch processing. Both are critical elements in our architecture.
- It provides excellent support for machine learning, also a key element of our architecture.
- It is a modern, cloud-centric product, mapping well to our architectural vision; we can run it inside Docker and it has pretty much all the connectors we need for our data sources and sinks.
- Lastly, Spark has a growing body of developers, and the community support is maturing.
Having said that, useful Spark advice can be sometimes hard to find. There are still many uses that are “uncharted” with zero previous experiences to guide your decisions. Like many of you, we’ve had to “invent the wheel”, so in the spirit of open-source collaboration, I wanted to share how we have used Spark Streaming to implement a dynamic sampling strategy.
The Batch Processing Time Problem
Spark Streaming is famously known as a “micro-batching” based architecture. This simply means that the streaming engine is built atop the underlying batch engine, where the streaming engine continuously generates jobs for the batch engine from a continuous data source. Each batch arrives in regular time increments defined by the application which could be as short as a few milliseconds or as long as a few minutes.
Because the source continuously sends data, the streaming engine needs to ensure it processes that data before the next batch gets queued up. If the arriving batches take longer to process than the batch interval time, a “snowball effect” could take place. Eventually, Spark Streaming runs out of resources to keep up with the backlog and simply gives up, stalling or killing the whole application. Obviously, it is extremely important to keep the following to be true most of the time:
Batch Processing Time < Batch Interval time
Many articles have been written on solving this problem for Spark Streaming applications that need to run 24×7. Spark Streaming is extremely flexible, with many knobs that can be turned to help keep the processing time in check. However, as many of you have learned, tuning Spark Streaming is notoriously hard and difficult to predict due to factors largely out of the direct control of a developer. These factors include (but are not limited to):
- Sustained spikes in incoming data rate.
- Resource crunch due to being deployed on a smaller cluster than is needed to support the workload, or a shared Yarn/Mesos cluster being used for other jobs.
- External systems such as target databases/message queues or hardware NICs, routers or disks that are slow and cause processing delays.
- Add to this the vagaries of the software stack itself; the OS, JVM and Spark as well as the application all of which contribute to uneven processing times.
Here is an example where an increase in the input rate causes the processing time to increase which leads to scheduling and total delay to quickly go beyond acceptable (input rate) limits:
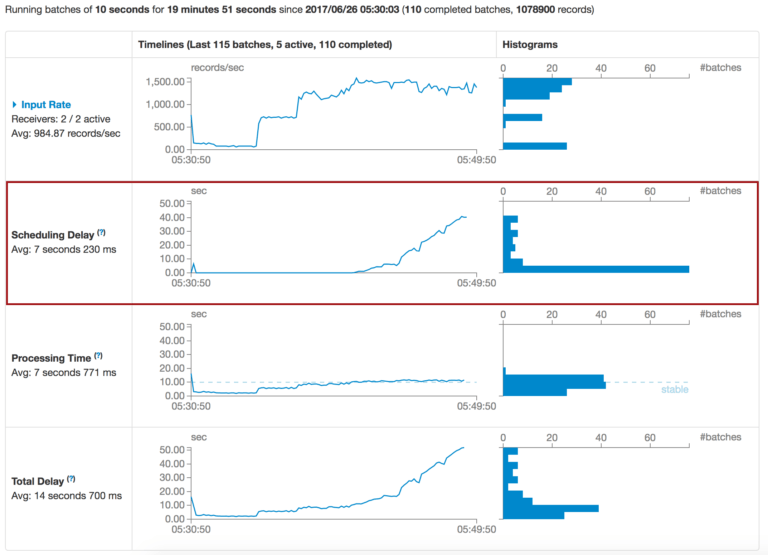
Fig. 1: Increased traffic flow results in an increase in total delay (avg. 7+ seconds) without dynamic sampling
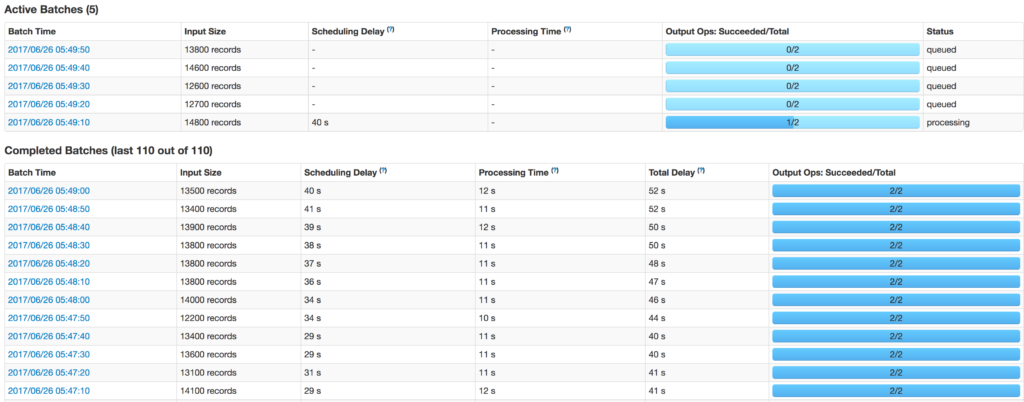
Fig. 2: Queued active batches without dynamic sampling
Given the input rate management challenge, an adaptive system that continuously monitors the data processing rate and appropriately reacts by changing the incoming data rate, seems like a more effective strategy. This approach involves measuring the processing rate and applying it to do one of the following:
- Apply backpressure on the source: Reduce or increase the rate at which records are picked up as processing rate changes. Any records not collected are retained by the upstream source and are delivered in subsequent batches.
- Dropping data: Pick up the full complement of records from the source but simply drop the first N records to meet the processing rate. This is only a slight variation on the sampling approach we will discuss below.
- Dynamic Sampling: A better way to reducing inbound data load would be to drop a random sample from the received batch. This is what we term as Dynamic Sampling since the sample size is dynamically adjusted to processing rate.
Dynamic Sampling: The Details
A Backpressure implementation was introduced in an earlier version of Spark (v1.5). It picks up a variable number of input records from the source by continuously measuring and updating an internal metric of how long each batch is taking to process. This is based on a software implementation of a PID Estimator. Learn more about the PID Estimator on Wikipedia and on GitHub using the link spark implementation. The PID Estimator is used to keep track of the current best estimate of how well the overall system is performing and the ideal number of records that should be processed in the next batch such that we keep meeting our goal:
Batch Processing time < Batch Interval time
Spark’s standard backpressure can be enabled by setting a configuration property:
SparkConf conf = new SparkConf();
conf.set("spark.streaming.backpressure.enabled","true");This works well for applications where the following criteria are met:
- It’s important to Processing each and every record, even with a delay is critical.
- Upstream source(s) can either absorb the backpressure or propagate it further up the chain where an eventual source of events can be throttled.
But what about applications that don’t meet the above criteria or specifically:
- Source(s) cannot absorb backpressure.
- It’s acceptable to drop a certain number of records in order to achieve the overall SLA at the expense of some accuracy.
While Spark Streaming does not have an implementation (yet) to meet these criteria, it’s straightforward to build one that works effectively.
Another useful concept from Spark Streaming is the StreamingListener. A class implementing this interface and registered to the SparkContext will be provided callbacks about various useful events. One of these events is a batch completion event where important information regarding the completed batch is provided. We can implement the method handling this event keeping track of how batch throughput performance and to provide a feedback mechanism to the application’s main loop to implement its own sampling.
The following code snippets shows one of the ways this can be implemented. We first define a class that can be instantiated once and used as a holder for the best estimate from the PID Controller for what the next batch size should be:
public class BatchSizeEstimate implements Serializable {
private long nextMaxBatchSize = 10000;
public long getNextMaxBatchSize() {
return nextMaxBatchSize;
}
public void setNextMaxBatchSize(long nextMaxBatchSize) {
this.nextMaxBatchSize = nextMaxBatchSize;
}
}Let’s extend the JavaStreamingListener (StreamingListener in scala). In this class, we will instantiate an instance of the internal Spark class PIDRateEstimator and use that in the onBatchCompleted() method to update the next estimate for the batch size.
import org.apache.spark.streaming.StreamingContext;
import org.apache.spark.streaming.api.java.JavaBatchInfo;
import org.apache.spark.streaming.api.java.JavaStreamingListener;
import org.apache.spark.streaming.api.java.JavaStreamingListenerBatchCompleted;
import org.apache.spark.streaming.scheduler.rate.RateEstimator;
import org.apache.spark.streaming.scheduler.rate.RateEstimator$;
import scala.Option;
public final class MyStreamingListener extends JavaStreamingListener {
private final BatchSizeEstimate batchSizeEstimate;
private final RateEstimator rateEstimator;
private final long batchDurationSeconds;
private long nextMaxBatchSize;
public MyStreamingListener(StreamingContext ssc, BatchSizeEstimate estimate) {
batchSizeEstimate = estimate;
rateEstimator = RateEstimator$.MODULE$.create(ssc.conf(),
ssc.graph().batchDuration());
batchDurationSeconds = ssc.graph().batchDuration().milliseconds() / 1000;
}
@Override
public void onBatchCompleted(JavaStreamingListenerBatchCompleted batchCompleted) {
final JavaBatchInfo completedBatchInfo = batchCompleted.batchInfo();
final long processingEndTime = completedBatchInfo.processingEndTime();
final long numRecordsReceived = completedBatchInfo.numRecords();
final long processingDelay = completedBatchInfo.processingDelay();
final long schedulingDelay = completedBatchInfo.schedulingDelay();
final Option computedSize = rateEstimator.compute(processingEndTime,
Math.min(numRecordsReceived, nextMaxBatchSize),
processingDelay,
schedulingDelay);
if (computedSize.nonEmpty()) {
nextMaxBatchSize = Double.valueOf(
scala.Double.unbox(computedSize.get())).longValue()
* batchDurationSeconds;
batchSizeEstimate.setNextMaxBatchSize(nextMaxBatchSize);
}
}
}Main Application code that sets up the Spark Streaming pipeline can then do something like the following:
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.api.java.JavaStreamingListenerWrapper;
public class TestApp {
public void setupSparkStreaming() {
JavaStreamingContext streamingContext;
// .... App Initialization code e.g. setup the spark context and streaming context.
final BatchSizeEstimate estimateProvider = new BatchSizeEstimate();
final MyStreamingListener streamListener = new MyStreamingListener(streamingContext.ssc(), estimateProvider);
streamingContext.addStreamingListener(new JavaStreamingListenerWrapper(streamListener));
// .... Any other code that sets up the processing
// Just a made up input DStream for illustration
JavaDStream stringJavaDStream = streamingContext.rawSocketStream("datasourcehost", 1234);
// Here we sample and transform the input DStream into the dynamically sampled DStream.
JavaDStream sampledJavaDStream = stringJavaDStream.transform(rdd -> {
long streamingMaxBatchSize = estimateProvider.getNextMaxBatchSize();
if (rdd.count() > streamingMaxBatchSize) {
double fraction = (double) streamingMaxBatchSize / rdd.count();
return rdd.sample(false, fraction);
}
return rdd;
});
}
//... Rest of the data processing code here.
}Note that the Spark Backpressure property spark.streaming.backpressure.enabled should be left as false for this sampling strategy to be effective.
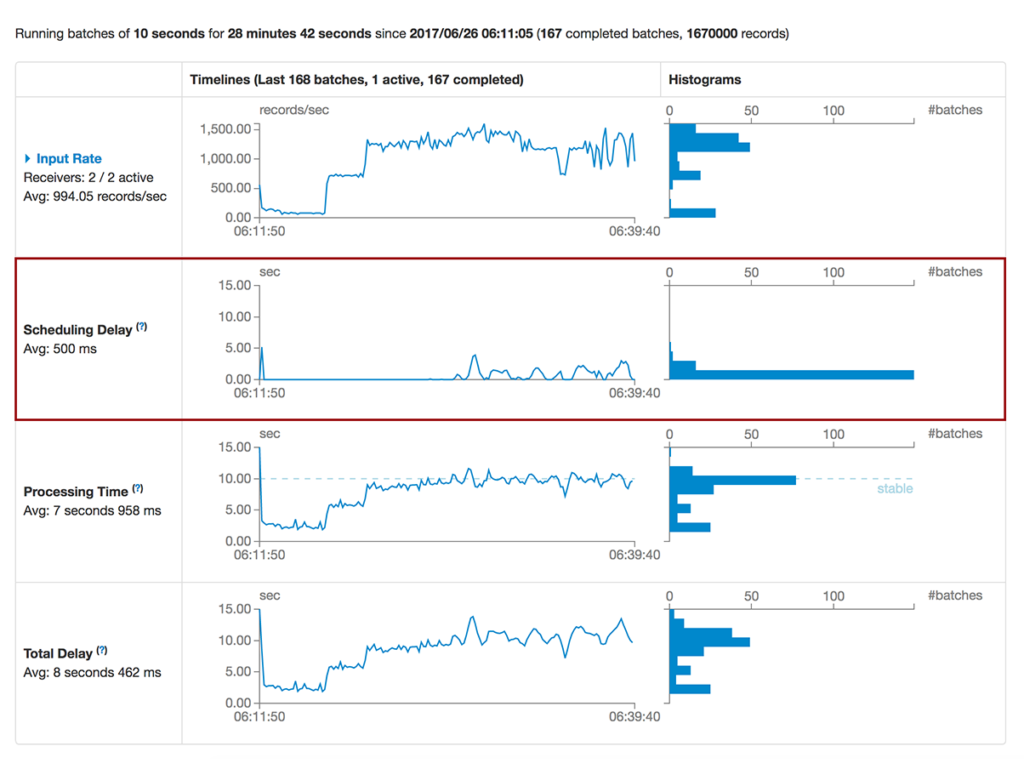
We re-ran the same application that we showed earlier in Fig. 1 and Fig. 2 and increased the input data rate in a similar fashion but with Dynamic Sampling turned on. And this is the resulting chart now:

Fig. 3: As traffic increases, total delay is lower (avg. 500ms) and more consistent with dynamic sampling
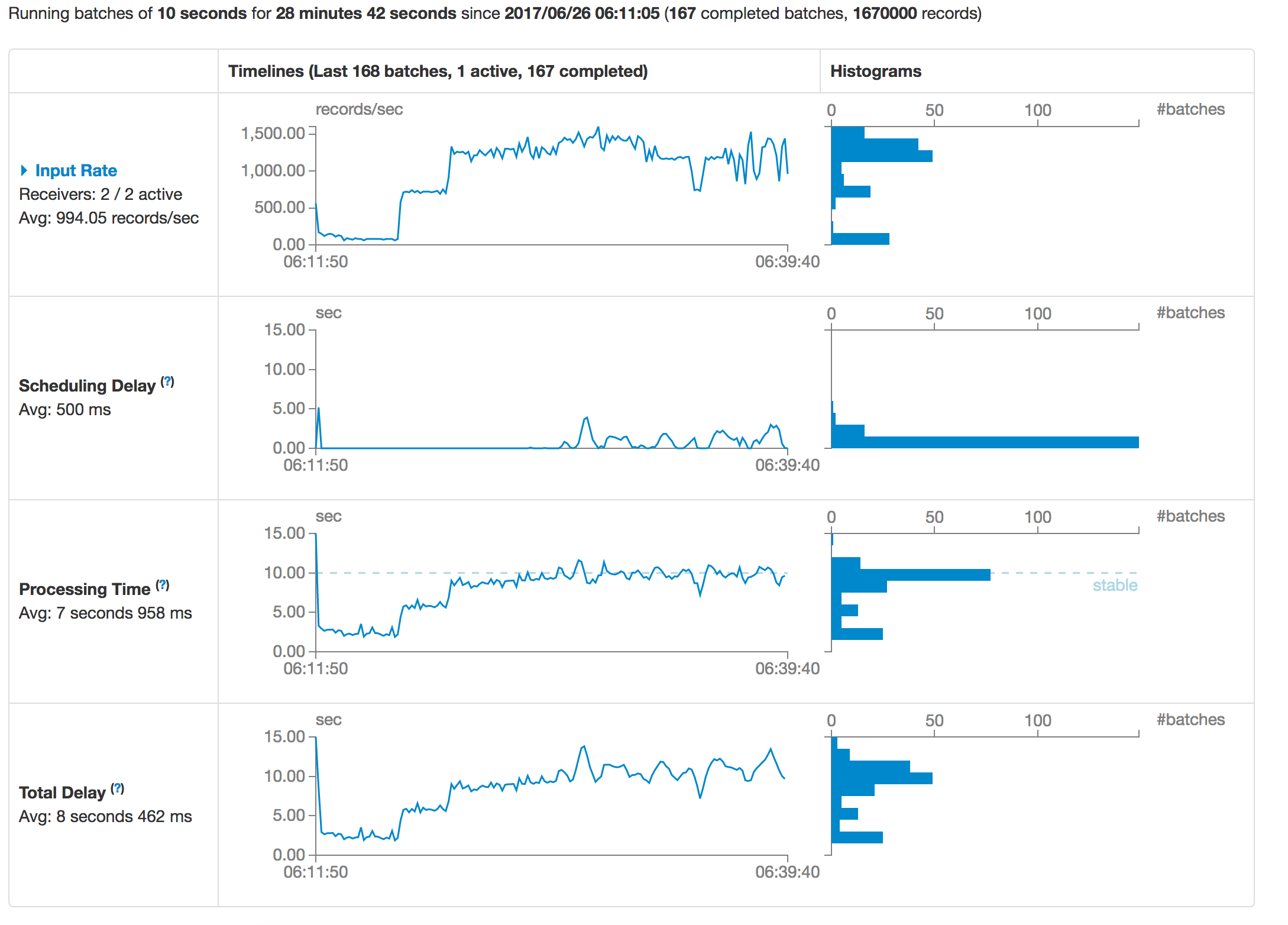
Fig. 4: Little or no queueing of active batches with dynamic sampling
As the images highlight, Dynamic Sampling helps keep the Processing Time and the Scheduling and Total Delays in check while not exceeding the target Processing time. It does so by continuously monitoring the throughput being achieved for recent batches and adjusting (up or down) how much data the application will process in the next batch. Spark Streaming is an important and exciting capability, but it needs a little care in managing it so that it works efficiently and performantly.
Good luck in your Spark Streaming Application development efforts.


