

The wide availability of attack components on the dark and public web makes it easy even for novice cybercriminals to conduct a successful attack on a website, API, or mobile application. With automated, ‘bot’ traffic quickly eclipsing legitimate user activity at some organizations, IT security teams, along with fraud teams, are keen to implement defenses to detect automated attacks using JavaScript injection. The goals of these two teams are similar, but their approaches are markedly different.
Fraud teams are mainly focused on discovering fraud by reviewing historical data, examining flagged transactions that need human analysis and rolling them back or canceling them if fraud is identified. In contrast, security teams are generally forward-looking, seeking to defend their environment from every future attack, which necessitates removing the human element from the process and acting automatically in real-time.
JavaScript Injection 101
There are two fundamental approaches to web application defense – one that focuses on changes to the web (or mobile) application and one that works stealthily on the server side. We are starting to see a shift by web application security products to stealthy, server-side detection, versus the traditional JavaScript (JS) injection method.
JavaScript injection is still commonly used as the standard approach, ironically, by both cybercriminals and many web application security companies. While it may detect and mitigate some attacks, there are several limitations and intra-organizational challenges that come with utilizing a JS-based approach.
The JS model works by inserting a script into your web application that “fingerprints” the user’s browser to differentiate between legitimate user activity and bot activity. When security solutions attempt to pinpoint anomalies across entire populations of large users or trends over extended periods of time, it’s common for them to use a combination of JS and a cookie to attempt to detect an automated attack. This mechanism requests that the client provide browser information so it can evaluate the user behavioral data from the session, such as whether mouse behavior is within the parameters of ‘human-like,’ in order to identify malicious automated activity or unwanted traffic.
Use Cases: Fraud vs. Security
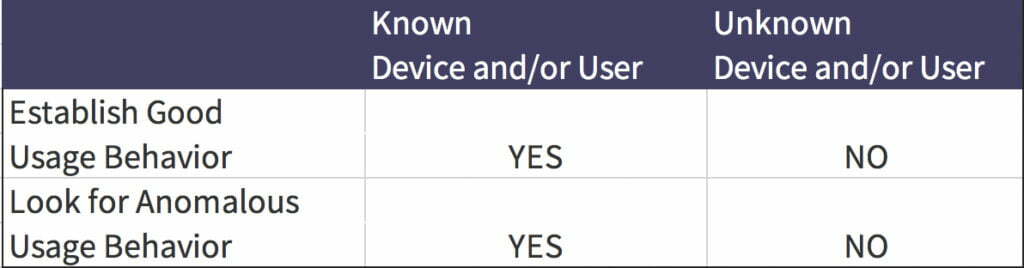
The two primary use cases for JS-based detection are fraud prevention and bot detection solutions. In many cases, these activities often come down to verifying a known user is who they say they are vs. identifying a new user or a new device.
A JS-based technique is useful in the fraud case where a user, their device, location and usage pattern are known. Since the solution has a log of a user’s history, a notable deviation from that history is a good cause to suspect fraud. However, when it comes to the security use case, JavaScript injection is not as effective.
Limitations: Web Application Security
The biggest challenge with a JS-based approach to security is its practicality in the real world. Deploying it requires coordination across at least three organizations; development (build the integration), operations (ensure performance and availability) and security (monitor attacks). Sometimes, marketing and fraud teams are involved as well. The required coordination for a single remediation between multiple departments with differing priorities can take weeks, leaving websites, mobile applications, and APIs vulnerable in the meantime.
Additionally, though the JavaScript is commonly obfuscated, its presence alerts attackers of a security mechanism. Once identified, attackers can study the client code and its communication with the host site. And, because JS code executes in the attacker’s environment, where there is no control or oversight, the tracking code is vulnerable to being spoofed in any number of ways once it is detected. The attacker can mimic the characteristics of a browser, user mouse and keyboard interaction (through recorded human sessions), leveraging IP addresses through botnets. Even if an initial attack is blocked, the attacker can modify the behavior of their client until an attack is successful and then scale their offense using botnets. The defender then tweaks their system for the new form of attack, and the cat-and-mouse treadmill keeps rolling.
Lastly, browser makers are in the best position to address the bot detection problem, particularly since the bots are masquerading as their products, and we are seeing an increased amount of R&D in this area. For example, Google’s Invisible reCAPTCHA is a milestone in bot detection. The question then becomes: why do web app security vendors need to duplicate this functionality and execute the same detection twice on one client?
Limitations Mobile, IoT & API Attacks
In addition to the pitfalls of long remediation cycles mentioned above, solutions that rely on client-side code commonly provide a mobile SDK that the organization’s development team needs to test for behavior, performance, and compatibility with its host application. As with any mobile application, each CPU cycle and MB of memory consumed impacts the smartphone’s performance, data usage, and battery life. The organization must then build the integration, roll it out to each of its users through Google Play and Apple App Store, and make its best attempt to get customers to keep their mobile clients up to date. This is not a simple endeavor.
For IoT (including gaming stations) and API-based attacks, all of these points are moot. The good news is that there is no client-side code to integrate, and the bad news is that there is no client-side code to detect. All of the organizational and integration challenges mentioned above go away, but the security product’s server-side detection must be powerful enough to detect an attack without impacting your normal partners’ usage of your API.
And if the server-side code is smart enough to provide protection against botnet attacks, that warrants the question: “Why do we need to rely on client-side code for security in the first place?”

Never miss an update!
By clicking Subscribe, I agree to the use of my personal data in accordance with Cequence Security Privacy Policy. Cequence Security will not sell, trade, lease, or rent your personal data to third parties.

